
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- julia
- drug muggers
- github
- single cell analysis
- 비타민 C
- DataFrame
- Git
- 싱글셀 분석
- HTML
- EdgeR
- js
- Bioinformatics
- PYTHON
- scRNAseq
- ChIPseq
- matplotlib
- cellranger
- pandas
- python matplotlib
- CUTandRUN
- drug development
- scRNAseq analysis
- CSS
- MACS2
- single cell
- CUT&RUN
- Batch effect
- ngs
- javascript
- single cell rnaseq
Archives
- Today
- Total
바이오 대표
[ Python pandas ] Dataframe을 groupby( ) - agg 이용해서 sum(합계), mean(평균값) 등 구하기 본문
Python/dataframe (pandas)
[ Python pandas ] Dataframe을 groupby( ) - agg 이용해서 sum(합계), mean(평균값) 등 구하기
바이오 대표 2022. 2. 25. 21:08
Pandas groupby( )
groupby( ) 를 이용해서 다음과 같은 기능들을 수행할 수 있다
- groupby( ) # object 객체 생성
- Aggregation # statistical summary (sum, mean, count)
- Transformation # group-specific 변형
- Grouping by multiple categories
- Resetting Index with as_index
- Handling missing values
보다 쉽게 이해하기위해 예시를 이용할 것이고 다음과 같은 Dataframe을 이용할 것이다.

groupby( ) object
data.groupby( ) 를 이용해서 원하는 column 으로 group 을 묶을 수 있다. 이는 DataFrameGroupBy object 객체를 만들어 낸다. 다음과 같은 Function들을 이용해서 해당 객체의 데이터 정보를 쉽게 확인 할 수 있다.
- group = data.groupby(' ')
- type( )
- group.ngroups # 그룹의 수를 보여준다
- group.groups # 각 그룹의 데이터 index를 보여준다
- group.size( ) # 각 그룹의 데이터 수를 보여준다
- group.get_group(' ') # 그룹에서 지정한 그룹의 데이터를 보여준다
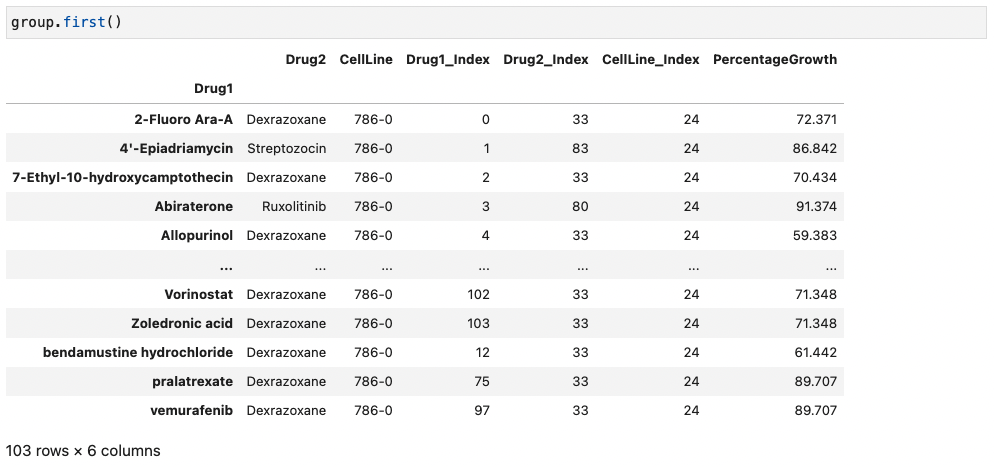
- group.first() # preview
예시) Dataframe을 Column "Drug1" 을 기준으로 group 하고 해당 데이터 정보를 확인하기



Aggregation
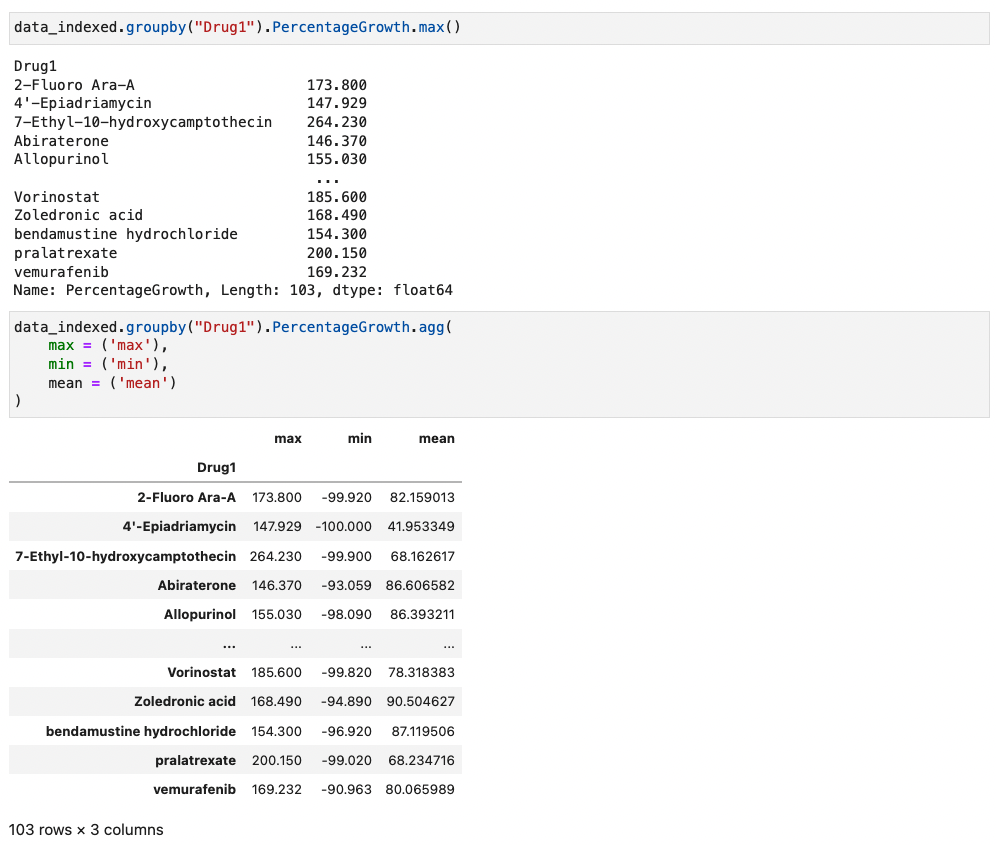
Statistical Summary 를 보여준다
- max( ), min( ), count( ), median( ), mean( )
- group.agg( ['max', 'min', 'count', 'median', 'mean']) # agg 를 이용하면 Dataframe 으로 만들 수 있다
예시) Dataframe 의 "Drug1"으로 그룹하고 해당 그룹의 "PercentageGrowth" 을 통계학적으로 계산
Transformation
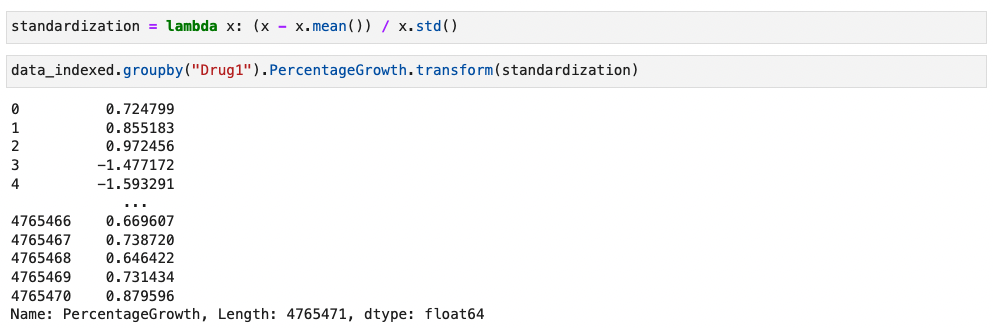
내가 직접 function을 만들어서 적용 할 수 있다
- .transform(function)
- .apply(function)
예시) 표준화 식을 만들어서 적용하기
Grouping by multiple categories
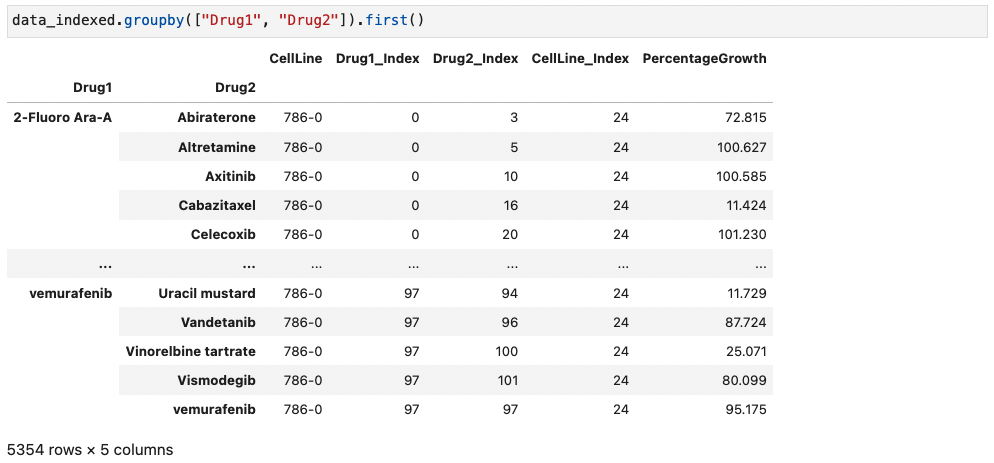
- df.groupby([" ", " "])
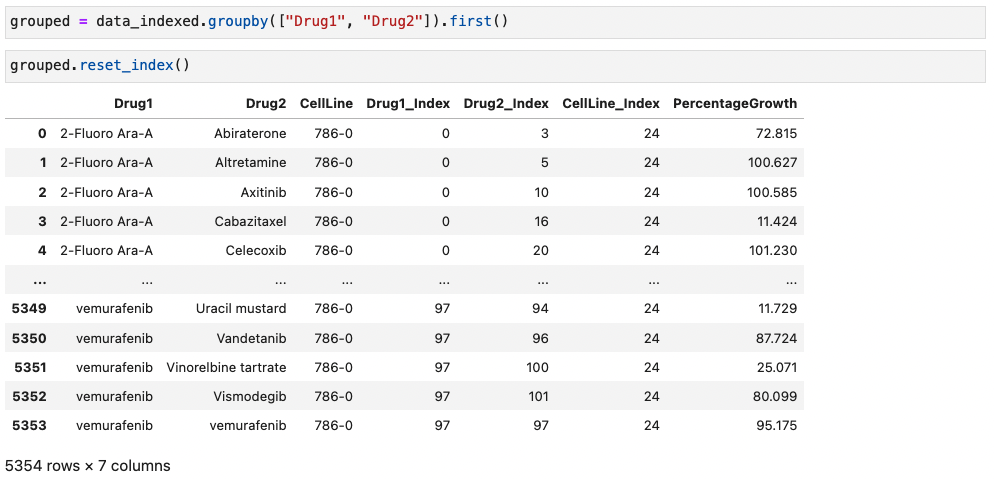
예시) 두개의 column "Drug1"와 "Drug2"를 이용해서 grouping
Resetting Index
- .reset_index( )
예시) 바로 위 예시를 이용해서 모든 데이터를 새로운 Index와 함께 보이게 하기
Handling missing values
- df.isna( ).sum( )
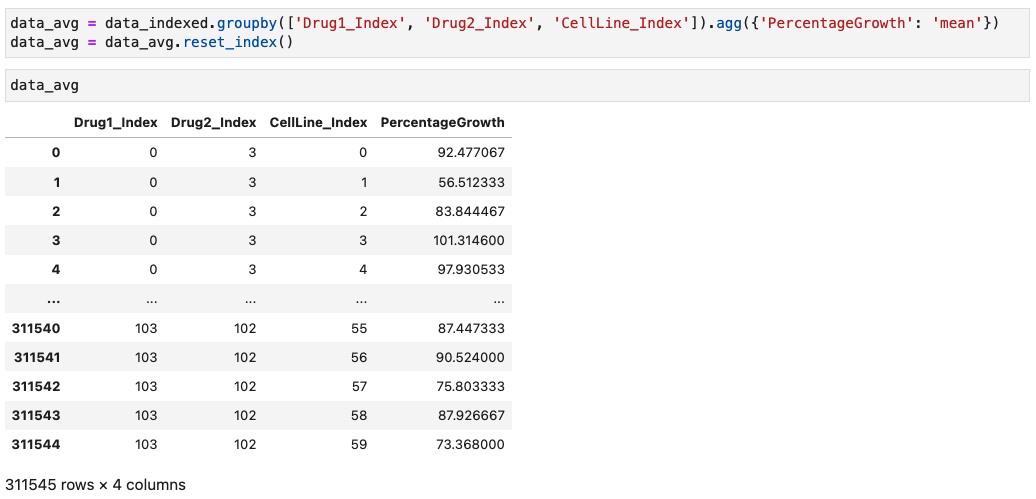
My Problem
[ "Drug1_Index", "Drug2_Index", "CellLine_Index" ] 이 같을 때 (중복될 때) "PercentageGrowth" 값의 평균값을 구하고자 한다.
'Python > dataframe (pandas)' 카테고리의 다른 글
| [ Python pandas ] Dataframe 에서 value 값 repalce 하기 (0) | 2022.02.18 |
|---|---|
| [ Python pandas ] Dataframe 에서 특정값 포함하는 row (열) 추출/삭제 (0) | 2022.02.16 |
| [ Python pandas ] Dataframe 을 List 로 변환하기 - to_list( ) / tolist( ) (0) | 2022.02.16 |
| [ Python pandas ] drop( ) - row/column 삭제하기 (0) | 2022.02.10 |
| [ Python pandas ] Dataframe 을 tensor (array) 로 변경하기 - df.values (0) | 2022.02.07 |
'Python/dataframe (pandas)' Related Articles
more



