
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- ngs
- Git
- pandas
- matplotlib
- CUT&RUN
- scRNAseq
- cellranger
- PYTHON
- single cell analysis
- Batch effect
- javascript
- CSS
- Bioinformatics
- single cell
- scRNAseq analysis
- DataFrame
- EdgeR
- 비타민 C
- CUTandRUN
- single cell rnaseq
- drug development
- HTML
- MACS2
- drug muggers
- python matplotlib
- github
- js
- ChIPseq
- julia
- 싱글셀 분석
Archives
- Today
- Total
바이오 대표
[ Python pandas] 작은 Dataframe에 더 큰 테이블에서 맞는 조건만 합치기 (= 합치고, 중복 제거) 본문
Python/dataframe (pandas)
[ Python pandas] 작은 Dataframe에 더 큰 테이블에서 맞는 조건만 합치기 (= 합치고, 중복 제거)
바이오 대표 2022. 1. 20. 08:00
목표: Disease_uniq 에 "ICD10_L" (from Disease)합치기
# Diesas_name 에 맞은 ICD10_L 만 찾아서 758 row 를 유지하면서 합치기

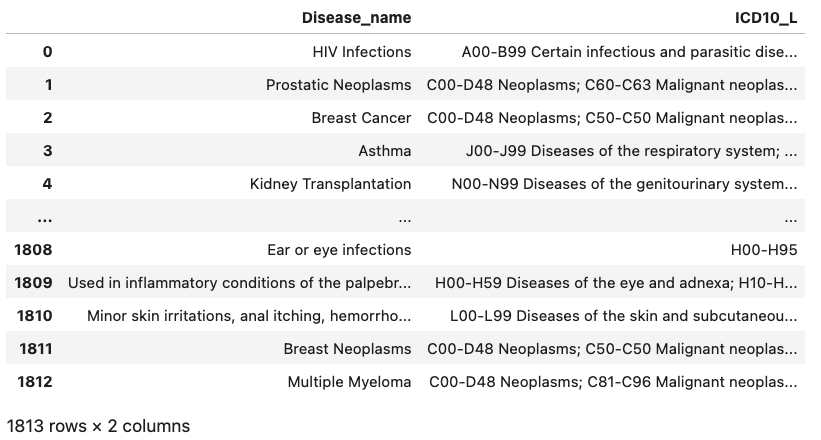
Merge, concat, join을 이용해도 다 중복적으로 합쳐지고 내가 원하는 모양이 나오지 않는다.
따라서 내가 알아낸 제일 쉬운 방법: 합치고 중복 지우기
[1] A.merge(B)
[2] drop_duplicates(subset = [" "])
따라서 해당 두 테이블을 합치기 위해서는
disease_all = disease_uniq.merge(disease) # how defalt = "inner"
disease_all = disease_all.drop_duplicates(subset = ["Disease_index"])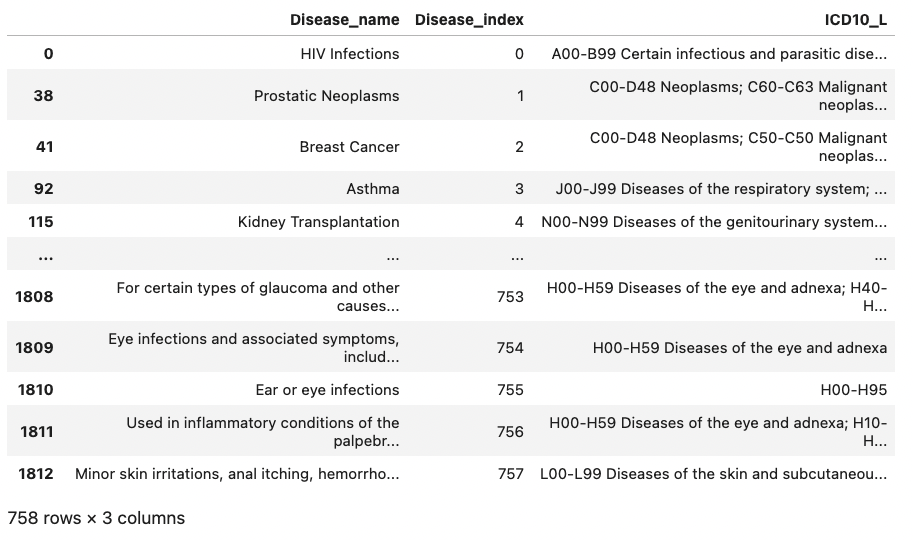
# row index 를 정리할수도 있다 reset_index()
disease_all = disease_all.reset_index(drop=True)
'Python > dataframe (pandas)' 카테고리의 다른 글
| [ Python pandas ] Dataframe 을 tensor (array) 로 변경하기 - df.values (0) | 2022.02.07 |
|---|---|
| [ Python pandas ] NaN 값이 포함되어있는 행 추출 - df.isna() (0) | 2022.02.07 |
| [ Python pandas ] 원하는 행, 열(iloc/loc), 값(iat/at) 추출 (0) | 2022.02.05 |
| [ Python pandas ] Dataframe row 제거 및 재배열 (drop(.index)), sort_values, reset_index) (0) | 2022.01.12 |
| [ Python pandas ] Dataframe 다루기 - unique, drop, fill, duplicate, merge (0) | 2021.10.07 |
'Python/dataframe (pandas)' Related Articles
more



